Is Google a Web Scraper?
Web scraping, also known as web harvesting, is a process in which computer programs collect information from the World Wide Web. Web scraping software may directly access the World Wide Web through a HTTP or a web browser. These programs are typically used for information retrieval and analysis. The process is similar to that of collecting information from a database.
AtSign
Web scraping is an increasingly popular method of obtaining data from e-commerce sites. It enables businesses to extract product pricing and other information, including reviews, from web pages. This data can help businesses make better decisions about their products and services and even help them decide the best time to launch a new product. Scraping also enables businesses to monitor and analyze trends and developments in the market.
Web scrapers can be structured or unstructured, and are designed to capture data from the web. They can extract data from web pages using a variety of techniques as well as no lag vpn, including HTML headers.
Amazon
Amazon is a popular ecommerce platform and has a number of services for its users. However, one major problem that Amazon has is that it doesn’t offer an easy way to export the data from its website. Instead of creating a manual process to collect data, you can use web scraping to extract the data you need and then export it to a spreadsheet or JSON file. It’s also possible to automate the process and collect the data continuously.
The downside of scraping Amazon is that the company has a limit on the number of pages you can access at a time. This means that if you want to scrape large amounts of data, you’ll need multiple servers. A solution to this problem is to host your scraper in the cloud, which allows you to scale the process as you grow. Another alternative is to use a message broker, which is another scalable framework that allows you to run multiple spider instances on one server.
ProxyCrawl
ProxyCrawl is a web crawling framework, which makes web scraping simple. It can be completed in a few lines of code, and is dependable, since it does not require website restrictions or CAPTCHAs. It also offers a Crawling API, which ensures reliability.
The ProxyCrawl web scraping platform offers a variety of features that make it a great tool for web scraping, you can purchase a pro version using your bnb wallet. For example, it can scrape data from worldwide locations. It makes use of advanced artificial intelligence (AI) to find relevant content. It also has hundreds of high-quality proxies in over 17 data centers.
It supports Python 2 and Python 3, and is available for Windows, Linux, and Mac OS X. After scraping a website, ProxyCrawl returns a response object with the data it has downloaded. However, scraping the web is not without its challenges. Some websites block requests, block IP addresses, or have other restrictions. As a result, a simple crawler may not be sufficient to scrape most web pages.
Amazon web scraper
An Amazon web scraper is a great tool to use for collecting data on Amazon’s price listings. Whether you need to perform research for your business, want to compare prices among competitors, or simply want to save time, an Amazon scraper is a great way to collect information. Using this tool is simple and easy, and you can get started quickly.
One major benefit of an Amazon web scraper is that it can collect product data for a business using the product’s category and name, without the need for coding. This tool is also flexible and will adapt to any changes in the Amazon site, so you can get as much data as you need.
Scraping the web is the process of collecting data from websites. Sometimes called web harvesting or web data extraction, web scraping involves the use of software that directly accesses the World Wide Web via HTTP or a web browser. The software then extracts data, such as product information, from websites.
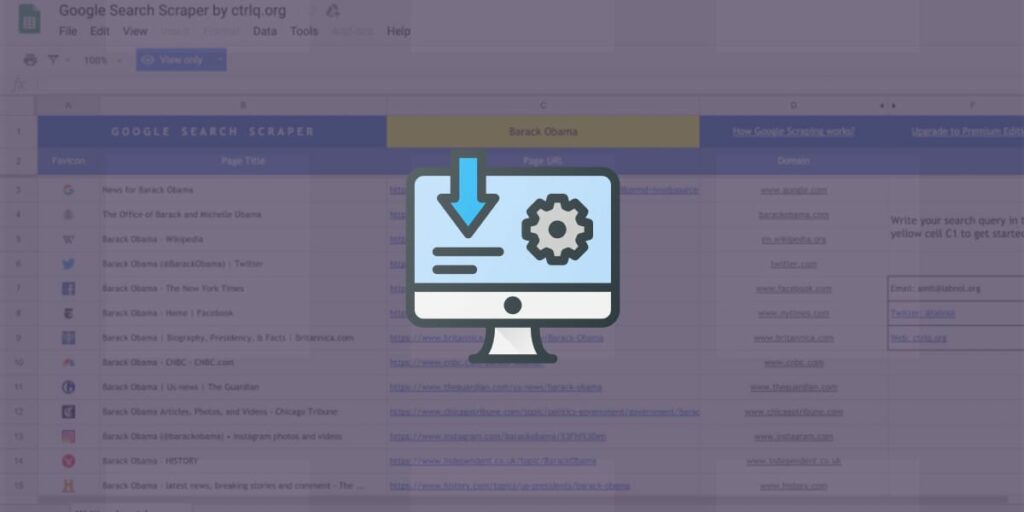
Google uses scraping to collect information from websites and show them in its search engine results pages. A Google scraper parses these results and highlights the most relevant content. The process is based on application programming interfaces (APIs). Google chooses the information that it deems valuable based on its own research and rankings. In this way, Google scraping is an efficient way to collect valuable information without the time and effort of manually scouring pages.
Using a Google scraper also allows businesses to develop competitive sales tactics. Using search scraping, companies can determine their page rank in search engine results and how many keywords they use to rank high. This competitive data allows companies to identify their strengths and weaknesses and to fill in gaps.
With a solid foundation in technology, backed by a BIT degree, Lucas Noah has carved a niche for himself in the world of content creation and digital storytelling. Currently lending his expertise to Creative Outrank LLC and Oceana Express LLC, Lucas has become a... Read more